2023. 11. 5. 00:39ㆍ논문 리뷰
- MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA
Make-A-Video: Text-to-Video Generation without Text-Video Data
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image
arxiv.org
Abstract + Introduction
Make-A-Video 논문의 모델은 제목의 "TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA" 라는 부분에서 알 수 있듯이, 텍스트를 입력으로 받아 비디오를 생성하는 모델입니다.
아마 글을 읽으시는 분들 중에는 Text-to-Image(T2I) Task에 더 익숙한 분들이 많으실 텐데요, Text-to-Video(T2V)는 그저 image 부분을 video로 바꾼 Task에 지나지 않습니다.
단, image가 아닌 video를 생성하는 모델을 처음부터 새로 구성하는 데에는 몇 가지 이슈가 존재하며, 논문에서 언급하는 이슈는 다음과 같습니다.
1. text-image가 pair를 이룬 데이터는 수 억 ~ 수십 억 장이 있지만, text-video pair 데이터는 이에 비해 상대적으로 적다.
2. 이미 Text-to-Image 분야에서 최근에 놀라운 성과를 거두고 있다.
위와 같은 상황에서, T2V를 위한 모델을 밑바닥부터 새롭게 구성할 필요가 없고, T2I 모델을 최대한 활용해서 T2V 모델을 구성하자는 것이 논문의 아이디어입니다.
조금 더 구체적으로 설명하자면, 많은 양의 text-image pair 데이터와 T2I 모델을 통해 text와 visual world 사이의 관계를 학습하고, unlabeled video data(즉, text가 달려있지 않은 비디오 데이터)를 이용하여 세상이 어떤 방식으로 움직이는지를 학습하면 text-video pair data 없이도 T2V를 잘 수행할 것이라는 이야기입니다.
Method

- Inference Scheme
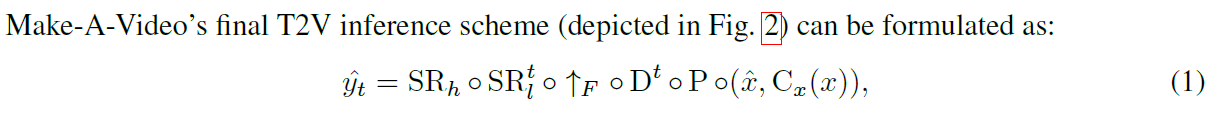
모델의 아키텍쳐에 대해 설명하기 전에 우선 모델이 비디오를 생성하는 inference scheme에 대해 살펴보도록 하겠습니다.
모델은 입력으로 들어온 text를 BPE 인코딩한 $\hat{x}$과 CLIP을 통해 임베딩한 $C_x(x)$을 Prior라는 네트워크에 넣어 image Embedding을 만들고, 이 image Embedding을 디코더에 넣어 16프레임의 64 $\times$ 64 resolution을 가지는 비디오를 생성합니다. 그 후 Frame Interpolation network, Spatiotemporal super-resoultion network, Spatial super-resolution network를 사용하여 생성된 비디오의 frame rate, resolution을 증가시키는 방식입니다.
논문에서 Frame Interpolation이나 super-resolution 관련된 부분은 자세히 다루지 않고, 가볍게 언급만 하고 넘어갑니다.
- Prior (T2I)
Prior 부분은 기존 T2I 모델을 활용하는 부분입니다. 논문에서는 이 Prior 부분을 dall-e-2에서 사용하는 core component를 공유하도록 설계했다고 하며 이 Prior를 text-image pair에 대해 먼저 훈련시킨다고 합니다.
※ 사견) T2I 모델인 Dalle-2에서는, text를 CLIP을 이용해 임베딩하여 text embedding을 얻고 이를 Prior라는 네트워크를 이용하여 image embedding 값으로 바꾼 후에, image embedding을 decode하여 이미지를 생성하는데, 이 부분의 Prior 네트워크를 이용한 것 같습니다. 아래는 dall-e-2 논문의 figure입니다. ※

- Spatiotemporal Decoder
이 논문에서는 Prior를 통해 얻은 image embedding 값을 video로 decode하는 방식으로 video를 생성합니다. image를 생성하는 디코더와 달리 video를 생성하는 디코더는 Spatial한 정보만이 아니라 Temporal한 정보까지 모두 고려해야 하기 때문에 Spatiotemporal Decoder라고 명명합니다.
디코더의 구조는 Pseudo-3D 방식으로 설계되었고, 크게 두 부분 Pseudo-3D Convolutional layer와 Pseudo-3D Attention layer로 구성됩니다. 디코더가 어떤 식으로 구성되어 있는 지 살펴보겠습니다.
- Pseudo-3D Convolutional Layer

우선 Convolutional layer입니다. video 데이터는 이미지와 달리 Frame에 대한 정보 또한 포함하고 있기 때문에 일반적인 2D Convolution보다는 3D Convolution(3D Conv)을 사용해야 하는데, 여기에서는 그냥 3D Conv가 아닌 Pseudo-3D Conv라는 방식을 사용합니다.
Pseudo-3D Conv 방식은 우선 각 프레임에 대해 2D Conv를 이용해 feature map을 추출하고, 이 feature map을 frame별로 쌓은 후에 frame 축에 대해 1D Conv를 하는 방식으로 구성됩니다. 즉, 2D Conv를 이용해 각 프레임에 대해 spatial 정보를 먼저 고려하고, frame 축에 대한 1D Conv를 이용해 temporal 정보까지 반영하는 방식으로 Spatiotemporal layer를 구성합니다. 기존 3D Conv와 달리 spatial 부분과 temporal 부분을 분리하였기 때문에 Pseudo-3D 방식이 됩니다.
이러한 Pseudo-3D Conv 방식의 장점은 다름 아닌 Computational cost가 줄어든다는 점입니다. 비디오의 경우 이미지와 달리 프레임에 대한 정보까지 있어 이미지에 비해 훨씬 더 많은 연산량을 필요로 하기 때문에, 이 논문에서는 이런 방식으로 연산에 들어가는 비용을 줄였습니다.
※ 사견) Pseudo-3D 방식을 통해 연산량을 줄인다는 부분은 상상해보시면 쉽게 아실 듯 합니다. 예를 들어 (frame, width, height)이 (100, 5, 5)인 텐서에 대해 3x3x3 3D Conv를 적용하는 경우와 Pseudo-3D Conv를 적용하는 경우를 비교해보면 연산량이 매우 줄어든다는 것을 확인하실 수 있으리라 생각합니다. ※
Pseudo-3D Conv layer에서 사용한 2D Conv 필터의 경우 pre-trained T2I 에서의 필터를 이용해 초기화하고, 1D Conv 필터의 경우는 identity function으로 초기화한다고 합니다. 1D Conv를 identity function으로 초기화 함으로써, spatial-only layer에서 spatiotemporal layer로 매끄럽게(seamless) 연결될 수 있게 만듭니다.
여기까지가 Pseudo-3D Conv layer에 대한 설명입니다. 다음으로는 Pseudo-3D attention layer에 대해 설명하겠습니다.
※ 사견) 2D Conv를 pre-trained T2I 모델의 필터 값으로 초기화하는 이유는 아무래도 많은 양의 데이터로 학습한 T2I 모델의 커널이 가지는 일반화 능력을 이용하고자 하는 것 아닐까 싶습니다. ※
- Pseudo-3D Attention Layer

논문에서는, 비디오 디코더에 Image Embedding을 사용하여 Cross Attention까지 적용합니다. 앞의 Pseudo-3D Convolution과 비슷하게 먼저 각 frame에 대해 Spatial attention을 적용한 후, 이를 쌓은 뒤 Temporal attention을 적용하는 방식입니다.
또, Pseudo-3D Conv layer와 유사하게 2D attention layer의 가중치는 pre-trained T2I 모델의 값으로 초기화 하고, 1D attention layer는 identity function으로 초기화하여 사용합니다.
◈ Spatiotemporal Decoder는 위와 같은 Pseudo-3D Layer로 이루어진 3D-Unet 구조로 구성됩니다.
- Frame Interpolation Network
- Fine-tuning a Spatiotemporal Decoder
제한된 메모리와 컴퓨팅 자원에서 frame rate을 높이기 위해, 논문에서는 기존 spatiotemporal decoder를 masked frame interpolation task에 fine-tuning 하여 사용합니다.
- Additional Input of the U-Net
Fine-tuning을 위해 추가적인 4 channels를 입력으로 넣는데, 각 채널의 의미는 아래와 같습니다.
- 3 channels: RGB masked video input
- 1 channels: binary channel로, 어떤 frame이 mask될 지를 지정
논문의 실험에서는 디코더에 의해 생성된 16 frame video를 fps 값을 condition으로 받아 frame skip 값을 5로 설정하여 76 frame video로 upsampling 했다고 합니다. ((16-1)*5+1 = 76)
- Training
모델의 전반적인 Training 방식에 대한 설명입니다.
- 가장 먼저, image에 대해 prior, decoder, two super-resolution network를 학습시킵니다. 여기에서 image에 페어로 붙어 있는 텍스트는 사용하지 않습니다.
- 다음으로, temporal layer를 추가한 뒤에 unlabled video를 사용하여 fine-tuning합니다. 여기서는 원본 비디오에서 16 frame을 샘플링하며, 원본 비디오는 1~30 사이 랜덤한 fps를 가지는 비디오입니다.
- 그 다음, masked frame interpolation network를 temporal decoder에 fine-tuning합니다.
Experiments
- Dataset for training
- Dataset - text-image pair: LAION-5b에서 영어로 된 text를 가지는 2.3B subset을 사용합니다.
- Dataset - video: WebVid-10M 데이터셋과 HD-VILA-100M에서 10M 만큼의 subset을 사용하며, aligned text는 사용하지 않고 비디오만 사용합니다.
- Evaluation Settings: Quantitative Results
- Zero-shot setting: UCF-101과 MSR-VTT 데이터 셋에 대해 zero-shot setting으로 평가합니다.
- For MSR-VTT
- FID와 CLIPSIM을 측정하며, CLIPSIM의 경우 video frames와 text 사이 평균적인 CLIP similarity 값을 측정하여 사용합니다.
- evaluation에 사용된 비디오는 16 x 256 x 256 비디오를 사용하며, 따로 frame rate이나 resolution을 증가시키지 않고 사용합니다.
- CogVideo와 Make-A-Video에 대해서 각 프롬프트에 대해 하나의 샘플만 생성하는 방식으로 비교합니다.

테이블을 보시면 MSR-VTT에서 학습한 GODIVA and NU¨WA보다 성능 좋으며, 같은 zero-shot setting으로 생성한 CogVideo보다도 성능이 좋다는 걸 알 수 있습니다.
- For UCF-101
- 각 class에 대해 하나의 template sentence만 사용합니다.
- FVD와 10K sample에 대한 Inception Score를 측정합니다.
- Finetuning Setting: CogVideo 모델의 경우 pre-trained model을 class-conditional video generation에 대해 fine-tuning하여 평가하였고, VDM 모델의 경우 UCF-101 데이터셋으로 모델을 처음부터 학습하여 unconditional generation을 수행하였습니다.

테이블을 보시면 zero-shot setting과 finetuning setting 모두 Make-A-Video가 우수하다는 걸 알 수 있습니다.
- Human Evaluation

Amazon Mechanical Turk(AMT) 서비스 사용해서 투표를 받았다고 합니다. 이 부분은 가볍게 넘어가겠습니다.
- Qualitative Results

(a)의 경우 VDM, CogVideo와 Make-A-Video의 T2V 능력을 비교하고, (c)에서는 FILM과 Make-A-Video의 Interpolation 능력을 비교합니다.
Discussion
- Limitations
마지막으로, 논문에서는 왼쪽에서 오른쪽 또는 오른쪽에서 왼쪽으로 손을 흔드는 사람이 있는 비디오처럼 비디오에서만 추론 가능한 텍스트와 현상 사이의 관련성을 학습할 수 없다는 자신들의 모델이 가지는 한계를 언급합니다.